پردازش دقیق تصویر،حروف، ارقام و اسناد با کمک دانش ایرانی
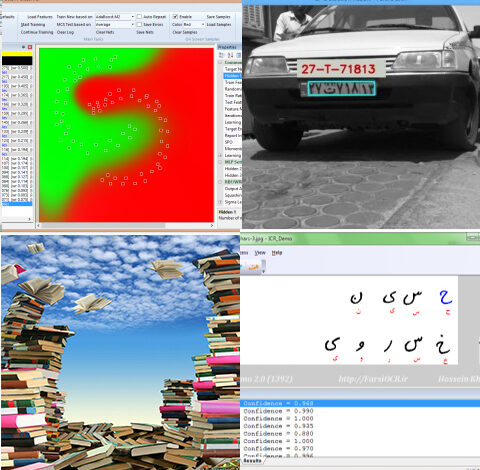
طراحی و نصب سامانه ستــپا (تشخیص پلاک ایرانی به زبان C) از جمله مهمترین دستاوردهای این محققان است؛ در این سامانه از تکنیکهای پردازش تصویر و شناسایی الگو کمک گرفته شده و با دقت و سرعت زیاد، موقعیت پلاک و حروف پلاک شناسایی میشود.
این سامانه در قالب یک کتابخانه قابل استفاده در زبانهای #C, C , C و دلفی است. برای برخی پردازشهای مقدماتی از قابلیتهای ساده OpenCV هم کمک گرفته شده اما بخش عمده برنامه مستقل از OpenCV است.
فرایند تشخیص موقعیت پلاک با استفاده از ترکیبی از روشهای ساختاری و هوشمند انجام شده و خطا در تشخیص موقعیت پلاک در شرایط نرمال  نزدیک صفر است؛ منظور از شرایط نرمال یعنی شرایطی که تصویر پلاک خیلی کوچک، خیلی بزرگ یا خیلی تاریک نباشد. برای تشخیص نویسههای پلاک هم از شبکه عصبی استفاده شده است که روی ارقام و حروف پلاکهای ملی آموزش دیده است.
نزدیک صفر است؛ منظور از شرایط نرمال یعنی شرایطی که تصویر پلاک خیلی کوچک، خیلی بزرگ یا خیلی تاریک نباشد. برای تشخیص نویسههای پلاک هم از شبکه عصبی استفاده شده است که روی ارقام و حروف پلاکهای ملی آموزش دیده است.
تشخیص الگو به کمک شبکههای عصبی
کتابخانه شبکه عصبی از دیگر طرح های پژوهشگران این دانشگاه است؛Pattern Classifier یک برنامه قدرتمند در زمینه تشخیص الگو به کمک شبکههای عصبی MLP،RBF و WRBF است. کاربر به کمک این برنامه و کتابخانه همراه آن می تواند الگوهای مورد علاقه خود را به راحتی آموزش داده و شبکه های آموزش دیده را در پروژه های C، دلفی و #C خود استفاده کند. روشهای AdaBoost M1 و AdaBoost M2 که به منظور تولید کلاسه بندهای تقویت شده است، در این برنامه به خوبی پیاده سازی شده و کاربر می تواند ترکیبهای متنوعی از شبکه های عصبی را تولید کرده و به دقت مطلوب دست یابید.
کافیست فایل ویژگی به فرمتی که قابل پذیرش در این برنامه است را تولید کرده و آموزش یک طبقه بند ایده آل را به Pattern Classifier بسپارید. این برنامه از نظر سرعت نسبت به نرم افزار متلب چند برابر سریعتر است و از نظر دقت هم نسبت به متلب برتری محسوسی دارد.
تولید طبقه بندهای شناسایی الگو(شناسایی ارقام دستنویس، شناسایی حروف دستنویس، شناسایی چهره، تشخیص حروف و ارقام پلاک خودرو، آشکارسازی چهره، تشخیص عیب در خطوط تولید پارچه، کاشی، بردهای الکترونیکی و موارد مشابه)، تخمین تابع دلخواه، پیش بینی سری زمانی مانند آب و هوا، قیمت طلا، قیمت سهام بورس و…. از جمله کاربردهای برنامهPattern Classifier است.
فرایند تشخیص موقعیت پلاک با استفاده از ترکیبی از روشهای ساختاری و هوشمند انجام شده و خطا در تشخیص موقعیت پلاک در شرایط نرمال نزدیک صفر است؛ منظور از شرایط نرمال یعنی شرایطی که تصویر پلاک خیلی کوچک، خیلی بزرگ یا خیلی تاریک نباشد.
نرم افزاری برای شناسایی ارقام و حروف دستنویس و پاسپورت
طراحی و نصب کتابخانه شناسایی ارقام و حروف دستنویس و پاسپورت از دیگر دستاوردهای محققان این دانشگاه است. سامانه شناسایی ارقام و حروف دستنویس، یک کتابخانه سریع و با دقت بسیار بالا است که می تواند انتخاب خوبی برای برنامه های پردازش فرم باشد. در این کتابخانه از ویژگیهای مختلف و طبقه بندهای متعددی کمک گرفته شده تا به دقت ۹۹٫۵ درصد برای ارقام دستنویس و بیش از ۹۷ درصد برای حروف برسیم. البته خطا در مورد حروف دستنویس غالبا ناشی از نقطه گذاریهاست. مثلا حرف«پ» اگر نقطه هایش کمرنگ باشد« ب» خوانده می شود و اگر از این خطاها که غالبا توسط پس پردازشهایی مانند مقایسه با مجموعه لغات، قابل رفع هستند، صرفنظر کنیم، دقت بیش از ۹۹درصد حاصل میشود.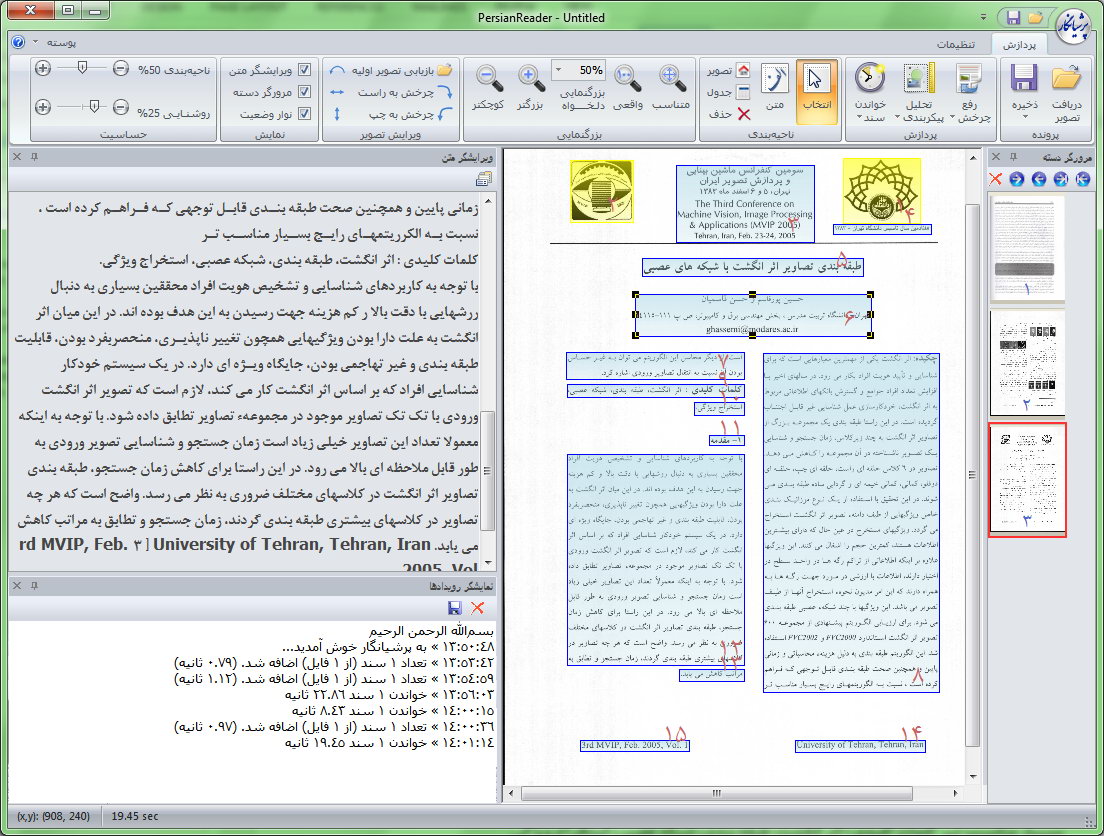
تبدیل اسناد چاپی به سایر متنها در کمتر از چند ثانیه
پرشیانگار از دیگر دستاوردهای این محققان است. پرشیانگار، یک سامانه OCR قدرتمند است که کاربر را از تایپ مجدد مستندهای چاپی بینیاز میکند؛ کاربر با استفاده از پرشیانگار میتواند در کمتر از چند ثانیه اسناد چاپی را با دقتی بیش از ٩۵ درصد به متنهای متناظر تبدیل کند. تنها کافی است صفحه مورد نظر را با دقت (درجه تفکیک) ٣٠٠ dpi اسکن و با کلیک روی دکمه(اسنادتان را بخوانید)، چرخش تصویر را اصلاح کند.
این سامانه می تواند نواحی مختلف متنی و تصویری را پیدا و قسمت های متنی را با دقت و سرعت تایپ کند. کاربر در صورت تمایل می تواند خود نیز به کمک ابزار ایجاد ناحیه، قسمت های مورد علاقه خود را تعیین کند تا سیستم تنها همان نواحی را بخواند.
پرشیانگار در دو نسخه پایه و نقره ای منتشر می شود. دقت بازشناسی بالای ٩۵درصد برای اسناد با درجه تفکیک ٣٠٠ نقطه بر اینچ، دقت بازشناسی بالای ٩٠درصد برای اسناد با درجه تفکیک ٢٠٠ نقطه بر اینچ، سرعت بالای بازشناسی(خواندن یک صفحه A4 در کمتر از ۴ ثانیه)، اصلاح خودکار چرخش تصاویر ورودی، تحلیل خودکار پیکربندی صفحه (یافتن نواحی متنی و تصویری)، قابلیت ایجاد و حذف نواحی مختلف به صورت دستی، ویرایشگر متنی داخلی، پذیرش تصاویر با فرمتهای BMP ، JPG، PNG، TIFF و سایر فرمتهای متداول به عنوان ورودی، پشتیبانی از 10 قلم مرسوم فارسی شامل نازنین، میترا، لوتوس، زر، یاقوت، ترافیک، هما، تیتر، تایمز و تاهما از جمله ویژگیهای نسخه پایه است.
نگارش نقرهای نیز شامل چند امکان جدید و رفع برخی نواقص گزارش شده در نگارش پایه است. از مهمترین امکانات این نگارش قابلیت خواندن متن های انگلیسی با دقتی بیش از ۹۶ درصد است. برای این منظور در بخش تنظیمات گزینه انتخاب زبان افزوده شده است تا کاربر زبان اسناد را انتخاب کند. در صورتی که متن غالب به زبان فارسی باشد و برخی لغات انگلیسی هم در متن باشد، با انتخاب زبان فارسی به عنوان زبان اصلی و انگلیسی به عنوان زبان دوم، امکان خواندن اسناد دو زبانه نیز فراهم می شود.
قابلیت مهم دیگری این نگارش، دریافت تصاویر از فایلهای PDF است. در این نگارش کاربر به راحتی می تواند فایل PDF با هر تعداد صفحه ای را بارگذاری کرده و متن آنها را بازشناسی کنید. امکان ذخیره سازی تصاویر و جدولهای موجود در سند به صورت فایلهای تصویری در کنار فایل متنی و تغییر کد رابط کاربری برای سازگاری کامل با نگارشهای جدید ویندوز از ویژگیهای دیگر این نگارش است.
گفتنی است، این طرح ها با سرپرستی دکتر خسروی، عضو هیات علمی دانشگاه صنعتی شاهرود انجام شده است.
گزارش: فرزانه صدقی