



مردم در طول زندگی خود با سؤالات متفاوتی مواجه میشوند و هرکسی سعی میکند پاسخ این سؤالات را به شیوهای مناسب یافته و مسائلش را حل کند. لذا بهطور طبیعی، به دنبال شخص خبرهای در آن حوزه میگردد تا بتواند سؤالش را مطرح نموده و تا آنجا که ممکن است، مسئله پیشآمده برای خود را حل کند. یکی از راهحلهایی که امروزه برای یافتن پاسخ سؤالات از آن استفاده میشود، بهکارگیری گروههای آنلاین است که در آنها میتوان یک بحث جدید را ایجاد کرد و سؤالات مورد نظر را در تبادل با افراد خبره پرسید.
یکی از راهحلهایی که امروزه برای یافتن پاسخ سؤالات از آن استفاده میشود، بهکارگیری گروههای آنلاین است که در آنها میتوان یک بحث جدید را ایجاد کرد و سؤالات مورد نظر را در تبادل با افراد خبره پرسید.
اما در اغلب موارد، پاسخهای متفاوت و گاهی حتی متناقضی به یک سؤال داده میشود. پس پیدا کردن یک جواب درست ممکن است امری چالشبرانگیز باشد. با توجه به این موضوع، یافتن شخص یا اشخاصی که در مورد سؤال موردنظر، اطلاعات کافی داشته و اصطلاحاً خبره باشند، اهمیت زیادی در چنین گروههای آنلاینی دارد. فرایند شناسایی چنین کاربرانی که بالاترین سطح تخصص را در حوزه خاصی از دانش دارند، میتواند توسط الگوریتمهای ریاضی خاص انجام شود.
در این خصوص، محققینی از دانشگاه صنعتی امیرکبیر در پژوهشی موشکافانه، به بررسی الگوریتمهای مختلف و مقایسه عملکرد آنها در پیدا کردن تعدادی متخصص در یک حوزه خاص پرداختهاند.
نوآوری این پژوهش، مقایسه 6 الگوریتم اصلی بر روی مجموعهای از دادههای بزرگ است که شامل بیش از یکمیلیون داده سؤال و جواب بوده و پیشپردازش آنها، کاری سخت محسوب میشود.
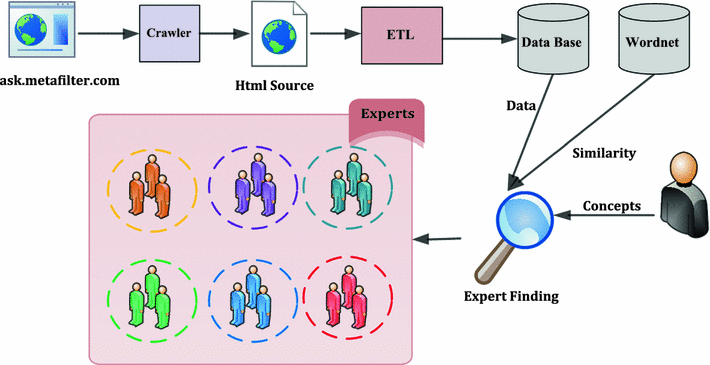
بدین منظور، محققین دانشگاه امیرکبیر، از مجموعه دادههای سایت اینترنتی Stack Overflow استفاده کردند که یک گروه بزرگ برای سؤال و جواب دستهای است. آنها، از رابط کاربری استخراج داده خود وبسایت استفاده کردند تا دادههای موردنیاز را استخراج کنند.
به گفته محققین فوق،الگوریتمهای زیادی برای یافتن افراد خبره در شبکههای اجتماعی وجود دارد که مشهورترین آنها شامل PageRank، HITS، In-degree و Z-score هستند.
بهنام بزرگی، دانشآموخته دانشکده مهندسی کامپیوتر دانشگاه صنعتی امیرکبیر و از مجریان این پژوهش در این رابطه به خبرنگار سیناپرس گفت:« الگوریتمهایی که مطرح شدند، بیشتر، الگوریتمهایی هستند که در شبکههای اجتماعی از آنها استفاده میشود. زمانی که شبکه اجتماعی را با استفاده از یالها و گرهها ترسیم میکنیم، یک سری تعاریف برای گرهها ارائه میدهیم و روابط بین افراد را با یالها و افراد را با گرهها ترسیم میکنیم. هر سناریویی هم قابل ترسیم است و بستگی به نوع نگاه شما به شبکه دارد. سناریویی که ما درنظر گرفتیم بدینصورت بود که گرهها افراد هستند و ارتباط آنها و درواقع یالها، پاسخهایی هستند که به پرسشهای افراد داده شده است».


این محقق افزود: «الگوریتمهایی که بررسی شدهاند، میزان مهم بودن هر گره را بررسی میکنند. هرچقدر گره پاسخدهنده اهمیت بیشتری داشته باشد، نشاندهنده این است که فرد، پاسخهای بیشتری به پرسشها داده و درنتیجه ما میتوانیم بهعنوان یک فرد خبره، امتیازهایی را برای او در نظر بگیریم . بنابراین هرچقدر امتیاز فرد بیشتر باشد میزان خبرگی او بیشتر خواهد بود. درواقع کل مفهومی که این روشها دارند، این است که برای گرهها در شبکههای اجتماعی، امتیازاتی را تعیین میکنند».
بزرگی تاکید کرد: «ما برای ارزیابی هر الگوریتم، 50 کاربر برتر را با توجه به امتیازی که براساس هر الگوریتم در بازه زمانی و در هر قسمت کسب کرده بودند، مرتب کردیم. ما همچنین 50 کاربر برتر را بر اساس امتیازاتی که با توجه به پاسخهای خود در سایت استک اورفلو دریافت کرده بودند، در بازه زمانی خاص و در یک قسمت خاص، مرتب کردیم. سپس ما کاربران برتر پیشبینیشده با الگوریتم را با کاربران برتر که از استک اورفلو استخراج کرده بودیم، مقایسه نموده و مشخص کردیم که چند کاربر معمولی در هر دسته 50 تایی وجود دارد».

یافتههای این تحقیق نشان میدهد الگوریتم Z-score با نسبت 84 درصد، بهترین عملکرد را در بین الگوریتمها به خود اختصاص داد.
همچنین بر اساس این نتایج، همه الگوریتمها بهجز الگوریتم PageRank نتایج تقریباً مشابهی داشتند، زیرا آنها فقط بر روی پاسخهایی که کاربر فراهم میکند، متمرکز هستند.
مجریان این پژوهش معتقدند: «سایت استک اورفلو، افراد را بر اساس امتیازاتی که گرفتهاند مرتب میکند. این امتیازات از رأی مثبت دیگر کاربران به دست میآید و این رأیهای مثبت، معمولاً از کیفیت جواب، معروفیت و بهترین جواب به انتخاب پرسشگر سؤال، به دست میآیند. به همین دلیل، PageRank بدترین عملکرد را در میان الگوریتمها داشت».
این محققان میافزایند: «دلیل اینکه الگوریتم Z-score بهترین عملکرد را در بین 3 الگوریتم باقیمانده داشت نیز این است که این الگوریتم، به خود سؤالی که توسط کاربر قرار داده میشود نیز توجه میکند و آنها را بهعنوان نشانهای از کم بودن یا زیاد بودن دانش آن فرد درنظر میگیرد».
بزرگی در خصوص کاربردهای دیگر الگوریتمهای مورد بررسی گفت: «این موضوع، بستگی به سناریو دارد. برای مثال وقتیکه شما در اینترنت در حال چرخیدن بین چند وبسایت هستید و سایتها را گره در نظر بگیرید و حرکت بین سایتها را یال، حالا میتوانید میزان مهم بودن هر گره و وبسایت را اینگونه تعیین کنید که چه وبسایتهایی بیشتر دیده شدهاند. سایتهای گوگل و یاهو برای رتبهبندی سایتها از چنین الگوریتمهایی استفاده میکنند. درواقع سایتی که بازدید بیشتری دارد را میتوان بهعنوان یک خبره و یا یک سایت با اهمیت بالا به شمار آورد. بهعبارتدیگر، مفهوم و کارکرد کلی این الگوریتمها، یافتن میزان اهمیت یک گره در یک شبکه است و لذا شما میتوانید در موارد مختلف از آنها استفاده کنید».
قابلذکر است بنا بر نتایج حاصله از این تحقیق، نشان داده شد که عملکرد هر الگوریتم به سناریو و ساختار شبکهای که در 

بزرگی در خصوص برنامههای آینده و تحقیقات بسط دهنده پژوهش فعلی اظهار داشت: «در پژوهش آینده میتوان به شکل دقیقتری پاسخها را محاسبه کرد. مثلاً متن پاسخ را در نظر گرفته و با استفاده از الگوریتمها، خود محتوی را بررسی کرد و نه امتیازات افراد را. زیرا ممکن است فردی پاسخهای زیادی داده باشد، ولی پاسخها در حد افراد مبتدی باشد و بهعلاوه، خود سؤال هم ساده باشد. همچنین میتوان برای سؤال، درجه پیچیدگی در نظر گرفت و به سؤالات سخت، رتبه بهتری داد. برای چنین موردی میتوان استفاده از کلمات کلیدی را مثال زد. هرچند کلمات کلیدی تنها عامل مهم دراینباره نیستند. چراکه ممکن است پاسخدهنده، تعدادی کلمه کلیدی را برای افزایش امتیاز، وارد پاسخ کرده باشد، ولی آنها درواقع قسمتی از پاسخ نباشند. لذا باید برای ادامه کار پژوهشی، نکات زیادی را در نظر گرفت».
این نتایج کاربردی و مفید، بهصورت مقالهای انگلیسی در نشریه بینالمللی Information Systems & Telecommunication، متعلق به پژوهشکده فناوری اطلاعات و ارتباطات جهاد دانشگاهی به چاپ رسیده است.
گزارش و گفتگو: دکتر محمدرضا دلفیه
منبع: Information Systems & Telecommunication